
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- YOLO
- Windows
- tx2
- Darknet
- 파이썬
- openCV
- 방법
- 텐서플로우
- agx
- 설치
- tensorflow
- 라즈베리파이
- Tistory
- cuda
- Xavier
- GPU
- DNN
- 딥러닝
- 애드센스
- 영상처리
- 물체검출
- ubuntu
- 엔비디아
- Nvidia
- Jetson
- 블로그
- 티스토리
- python
- Linux
- openpose
엔지니어스 - Engineeus
Darknet YOLO(You Only Look Once) 공부했다. Yolov3 본문
Darknet YOLO(You Only Look Once) 공부했다. Yolov3
Engineeus 2019. 12. 14. 21:31start()
{
YOLO 란?
You Only Live Once가 아닌, You Only Look Once의 약어로 Joseph Redmon이 워싱턴 대학교에서 여러 친구들과 함께 2015년에 yolov1을 처음 논문과 함께 발표 했습니다. 당시만 해도 Object Detection에서는 대부분 Faster R-CNN(Region with Convolutional Neural Network)가 가장 좋은 성능을 내고 있었습니다.
Yolo는 처음으로 One-shot-detection 방법을 고안하였습니다. 이 전까지는 Two-shot-detection으로 Object Detection을 구성 하였는데 실시간성이 굉장히 부족했습니다. 5~7 FPS를 가지고 어디에 쓰기 부족했죠. 그럼 Two-shot-detection과 One-shot-detection의 차이는 뭘까요?
제 다른포스트에 포스팅 해두었으니 꼭 확인 하고 넘어가시기 바랍니다.
최신 Object detection의 역사
아래 표를 보면 한눈에 Object Detection 알고리즘들의 역사를 볼 수 있습니다. 아래 표는 DNN(Deep Neural Network)의 역사를 나타내었는데 정말 몇년만에 엄청나게 많은 알고리즘들이 나오게 되었고 현재 진행형 입니다.

딥러닝을 이용한 Object Detection의 역사를 보자면 일반 CNN -> R-CNN(0.05 FPS ) -> Fast R-CNN(0.5 FPS) -> Faster R-CNN(7 FPS) 이라고 보면 됩니다. 이런 시국에 YOLO라는게 등장하면서 45~155 FPS를 보여주어 엄청난 결과를 이루었습니다.

위 그래프를 보면 Yolo가 상위의 FPS도 높으며 상위 mAP(정확도)를 갖는 걸 볼 수 있습니다.
-
아래는 YOLO 논문 발표 영상
https://www.youtube.com/watch?v=NM6lrxy0bxs
심심하신 분들은 보면 됩니다. CVPR에서 소개 할 때의 영상 입니다. 무튼 영상에서 하는 말은 무지하게 빠른 디텍터라고 합니다.
-
아래는 YOLO의 데모 영상
현재는 YOLO v1 -> YOLO v2 를 거쳐 YOLO v3까지 나와 있습니다.
그럼 궁금하시겠죠 왜 YOLO가 빠른걸까!? 자 이제 One(Single)-shot-detection의 원리를 파고 들어 봅시다!
Theory of YOLO
기존 Object Detection은 Classification 문제를 2단계를 나눠 검출(Two-shot-detection) 하여 정확도가 높았지만 네트워크를 여러번 호출 하였기에 속도는 아주 느렸습니다.
하지만 YOLO는 One-stage 검출기를 이용 하여 조금은 정확도가 떨어지지만 엄청나게 빠른 검출기를 만들어 냈습니다. 즉, 하나의 이미지를 딱 한번만 신경망을 통과시켜 엄청나게 빠른 속도의 검출기를 만들어 낸 것 입니다. (one-stage-detection은 아래서 설명)
(two-stage-detection과 one-stage-detection에 궁금하다면 여기를 참조해 주십시오.)
- 그럼 YOLO의 검출 방법은?
yolo에 검출 방법에 대해 자세히 설명한 Youtube를 통하여 설명 해 드리겠습니다.
위의 영상은 딥러닝의 유명한 교수님이신 앤드류응(Andrew Ng)입니다. 영어라 좀 이해가 안가는 분들이나 좀 더 자세히 알고 싶은 분들을 위해 제가 아래 설명으로 자세히 써 두었습니다.
참고로 위 설명은 YOLO 초기 모델을 기반으로 한건지 현재 Yolov3랑 다른 설명이 있습니다. 예를 들면 위에선 Bounding Box당 모든 Class Probability 값을 갖는데 Yolov3에선 각 셀당 Class Probability 값을 갖게 됩니다.
기본 설명
Grid 분할!
아래 그림과 같이 YOLO는 처음에 여러 격자(grid)로 그림을 S x S로 나눕니다. (논문에선 7 x 7의 격자로 분할 합니다.) 앤드류응 교수님의 강의에선 3 x 3 의 grid cells로 나눕니다.
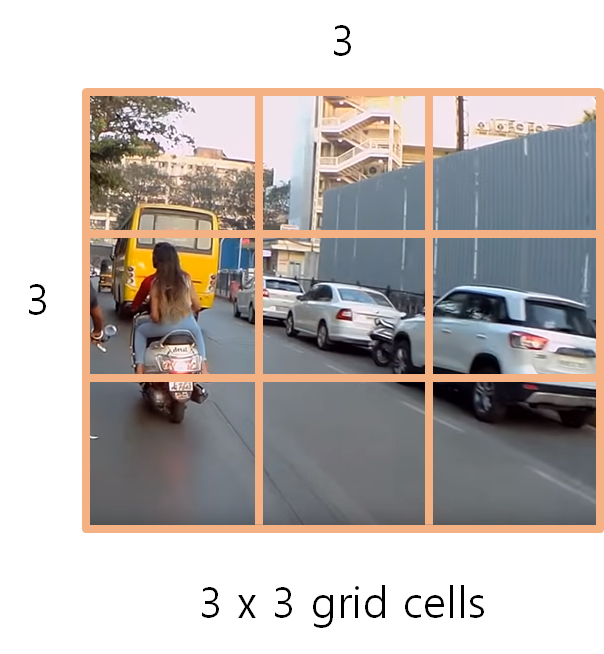
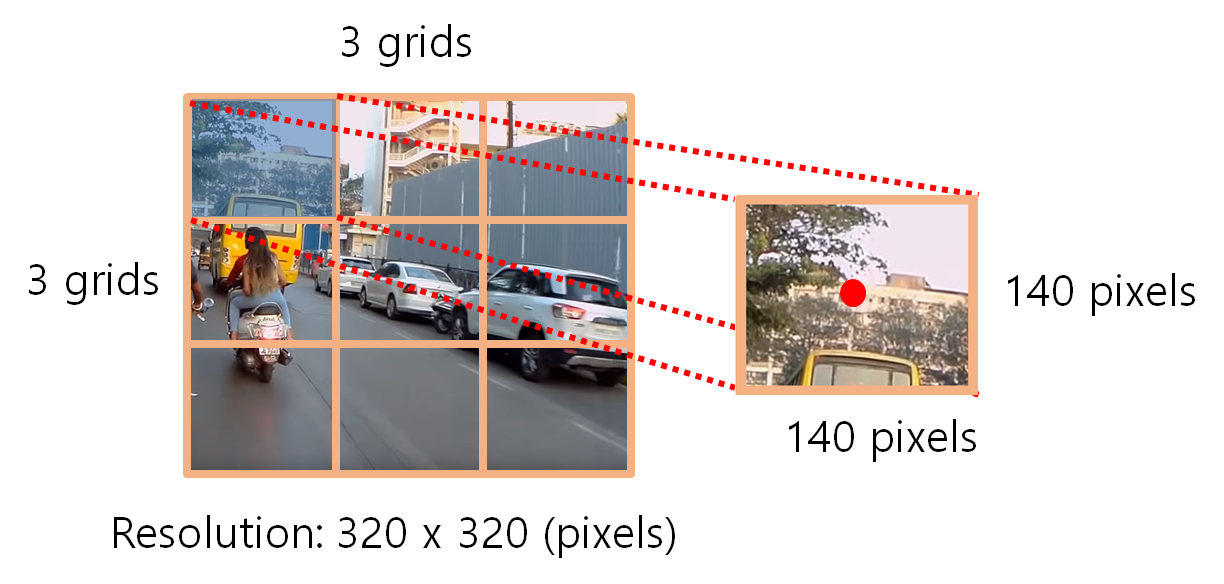
그렇게 되면 아래와 같이 한 셀의 정보를 갖게 됩니다. 각 cell도 각각의 pixel size와 중앙점을 갖게 됩니다. 아래는 첫번째 cell을 예시로 떼어내어 봤습니다.
Anchor Box
또한, 각각의 cell에서는 Anchor Box (cell과 Anchor는 다름)라는 것은 가집니다. 이는 개발자의 마음에 달렸지만 동영상에선 2개의 Anchor Box를 갖고 있다고 합니다.
(※ Anchor Box는 Bounding Box, Boundary Box, Window 등 여러가지로 불립니다.)

Anchor Box는 보통 1:1, 1:2, 2:1등의 비율이 정해져 있고 크기가 다른 박스들이 있습니다. 정하기는 개발자 나름이겠죠.
anchor[] = {10, 10, 10, 20}
위와 같이 배열을 만들어주면아래와 같이 비율적으로 정할 수 있겠죠. 픽셀 사이즈로 정해주면 됩니다.

Anchor Box의 정보!
이 Anchor Box의 정보인 아래 변수(parameter)이 정말 중요합니다.
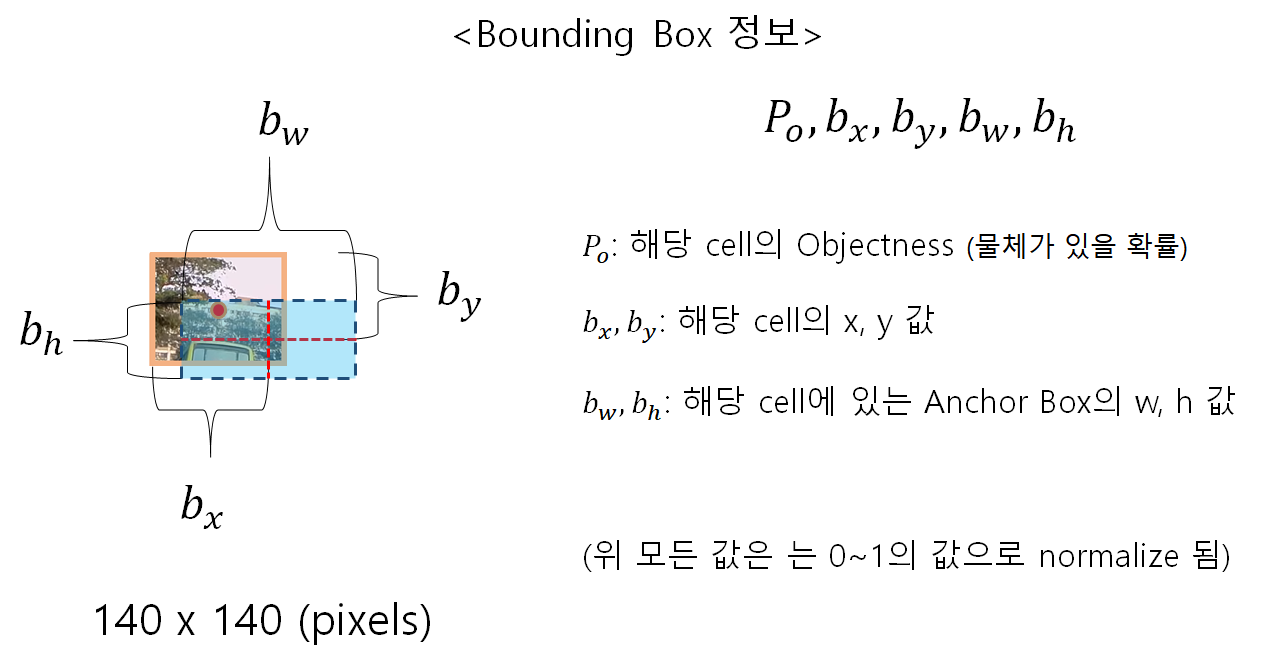
- bx와 by는 셀의 왼쪽 위 모서리에서부터 거리 입니다.
- bw, bh는 Anchor(Bounding Box)의 w, h값입니다.
- Po는 해당 Box으 Confidence Score(=objectness)이라는 물체가 있을 확률 입니다.
Grid Cell의 정보!
각 셀에선 Class Probability + Bounding Box Parameter (Bx, By, Bw, Bh, Po)로 구성 됩니다. Bounding Box가 많다면 더 추가가 되겠죠.
Bounding Box 파라미터는 위에서 설명을 했고, Class Probability에 대해서 설명 해드리겠습니다.
클래스가 3개라고 가정 합시다.
c1, c2, c3 : 해당 Bounding box가 클래스별로 몇퍼센트를 갖는지에 대한 파라미터 입니다.
(차: 0.3(30%), 동물 0.2(20%), 사람 0.5(50%) 이런식으로)
그러면 3개가 될테고 Bounding box가 2개가 아래처럼 있으면 총 3 + 5 + 5가 되는 것 입니다.
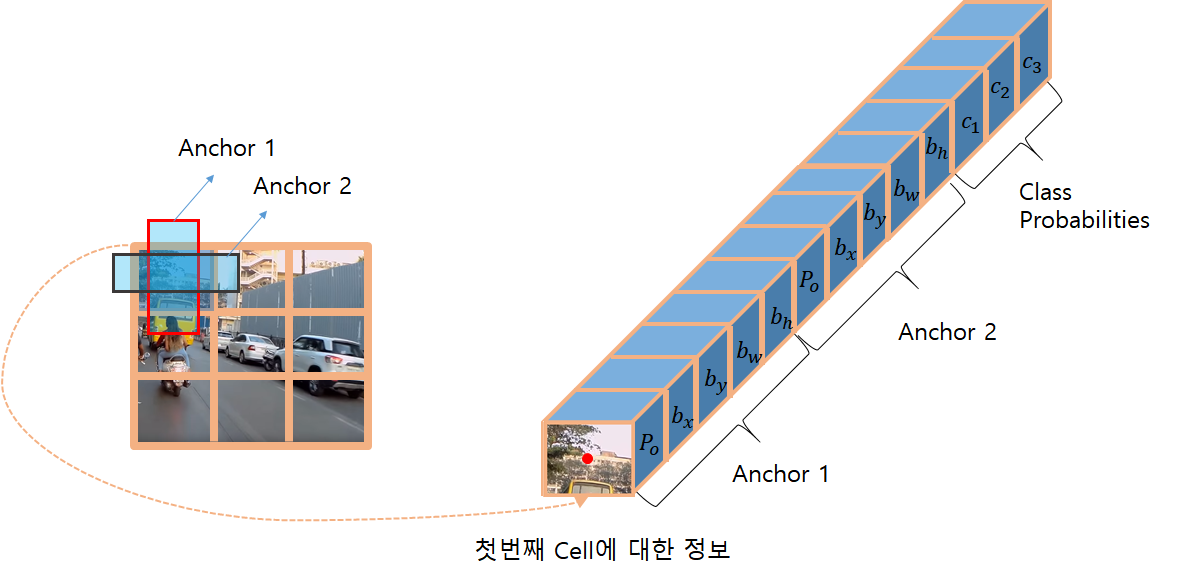
최종 파라미터!

위 설명은 각 명칭에 대한 설명이며, 이 파라미터를 가지고 아래 YOLO 결과 도출 순서에서 Yolo검출방법에 대해 자세히 살펴보겠습니다.
<YOLO 결과 도출 순서>
1. Letter Box Image 생성
원본 이미지는 보통 4:3 또는 16:9를 갖습니다. 하지만 네트워크 input은 608x608 이런식으로 사각형을 갖게 되므로, 비율이 다르게 된 이미지를 그대로 넣을 경우 모양이 찌그러질수 있습니다. 따라서 여분을 매꿔주는 이미지를 새로 생성 하는 작업을 Letter Box Image라고 합니다.

2. GoogLeNet에 입력 이미지를 넣어 줍니다.
이때 Trained Data(Weight) + Network Model + image가 Input으로 들어가게 됩니다.
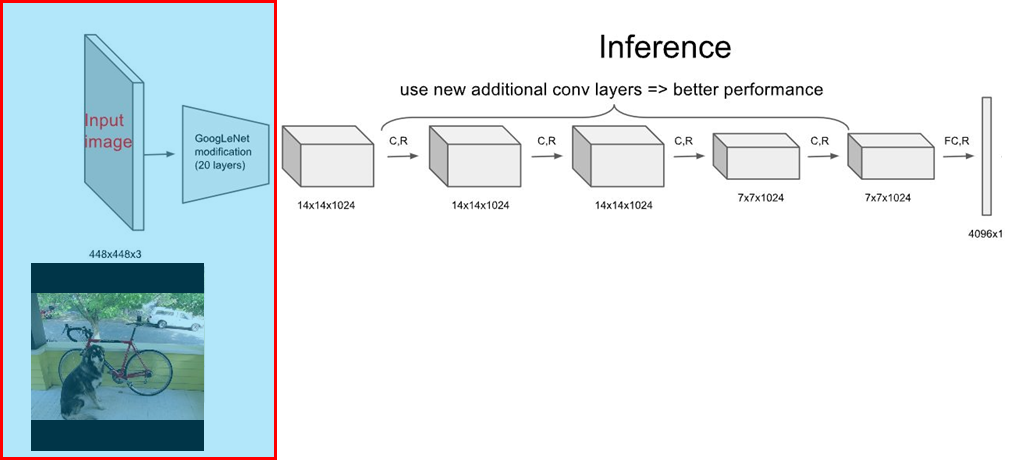
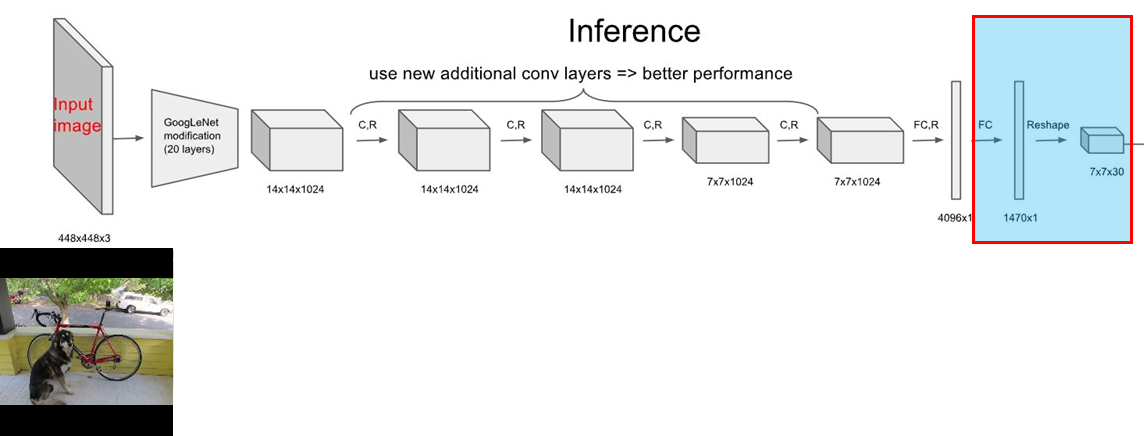
3. Fully Connected Layer를 아래의 순서로 설정한 Grid Cell크기에 맞게 변형하여 줍니다.
1470의 Tensor를 갖는 FCL(Fully Connected Layer)로 변경 한 이유는 7 x 7 x ((2 x 5) + 20) = 1,470개 이기 때문입니다. 저 계산식은 (S x S x ((B x parameters) + class numbers))에서 나옵니다. (여기서 parameters는 Po, Bx, By, Bw, Bh)
따라서, 7 x 7 x ((2 x 5) + 20) = 1,470개의 텐서 생성
(위에 대해선 추후 자세히 설명 합니다.)
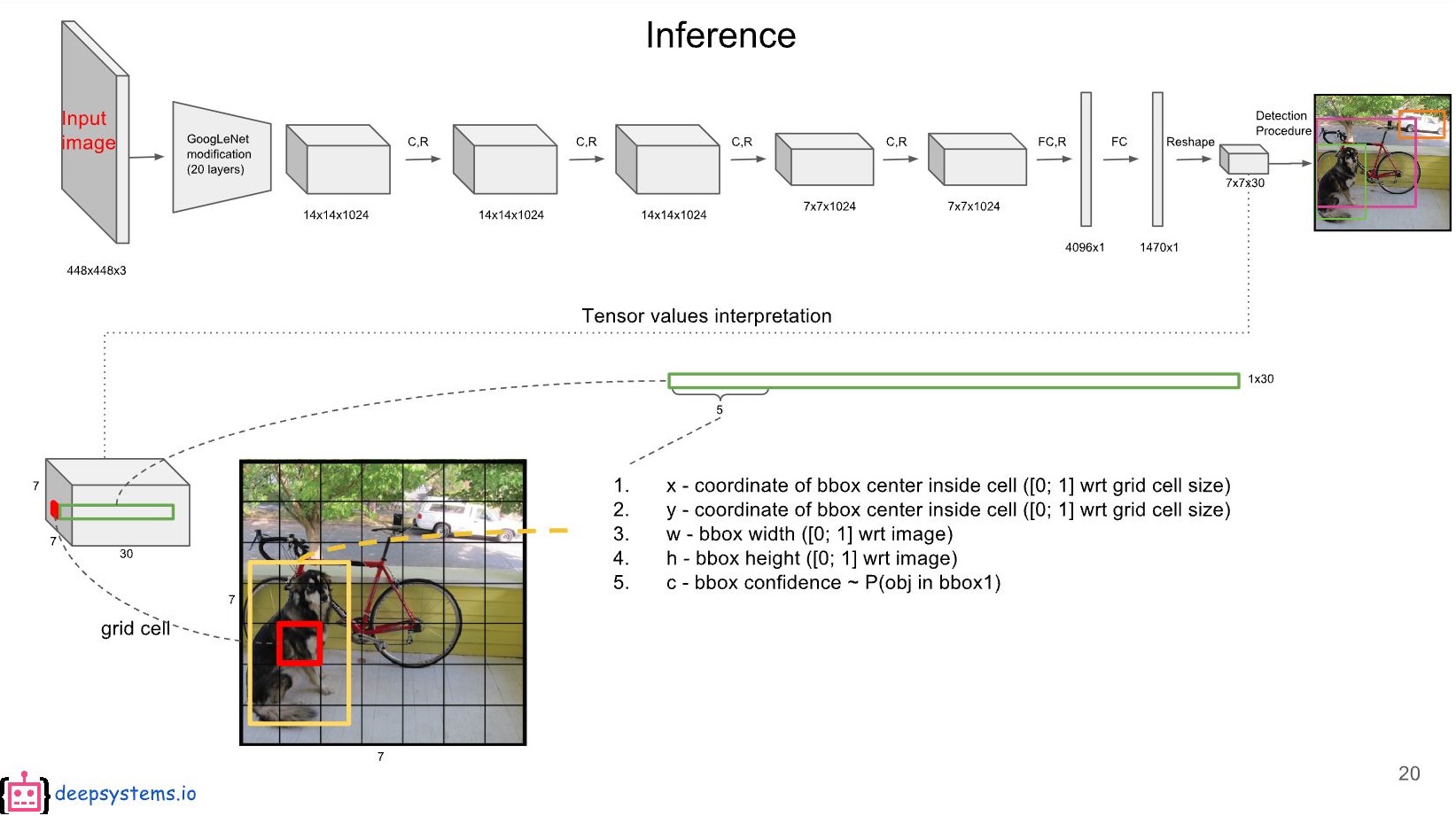
4. 각 Bounding Box에 대한 Class Confidence Score를 계산 한다.
4-1) 인풋을 S x S로 나눕니다. (S는 Grid Cell)
본 글에서 S = 7 (따라서 7 x 7 그리드 셀)
4-2) Bounding Box Parameter 구하기
- 각 '그리드(셀)'는 B 개의 Bounding Box가 있습니다. (B는 Bounding Box = Anchor = Window)
- 본 글에서 B = 2
- 각 'Bouding Box'는 5개의 파라미터(Bx, By, Bw, Bh, Po)를 갖습니다.
*Bx, By : 각 그리드의 왼쪽위 모서리에서부터 Bounding Box의 중앙점 까지의 거리 (0~1 사이의 값으로 정규화)
*Bw, Bh : 각 Bounding Box의 크기. 본 크기는 화면 전체 이미지를 기준으로 함. (0~1 사이로 정규화)
*Po : confidence score (=objectness)
*여기서 Po는 개발자가 Threshold를 정해서 일정수준 이하의 정확도를 가지면 제외 시키고 다시 찾는 방식을 가집니다. 계속 찾다 없으면 그 Anchor(=Bounding Box)는 0의 값을 갖겠죠.
4-2-1) 첫번째 Bounding Box
각 그리드에 위에서 설명한 5개의 파라미터가 나열 됩니다.
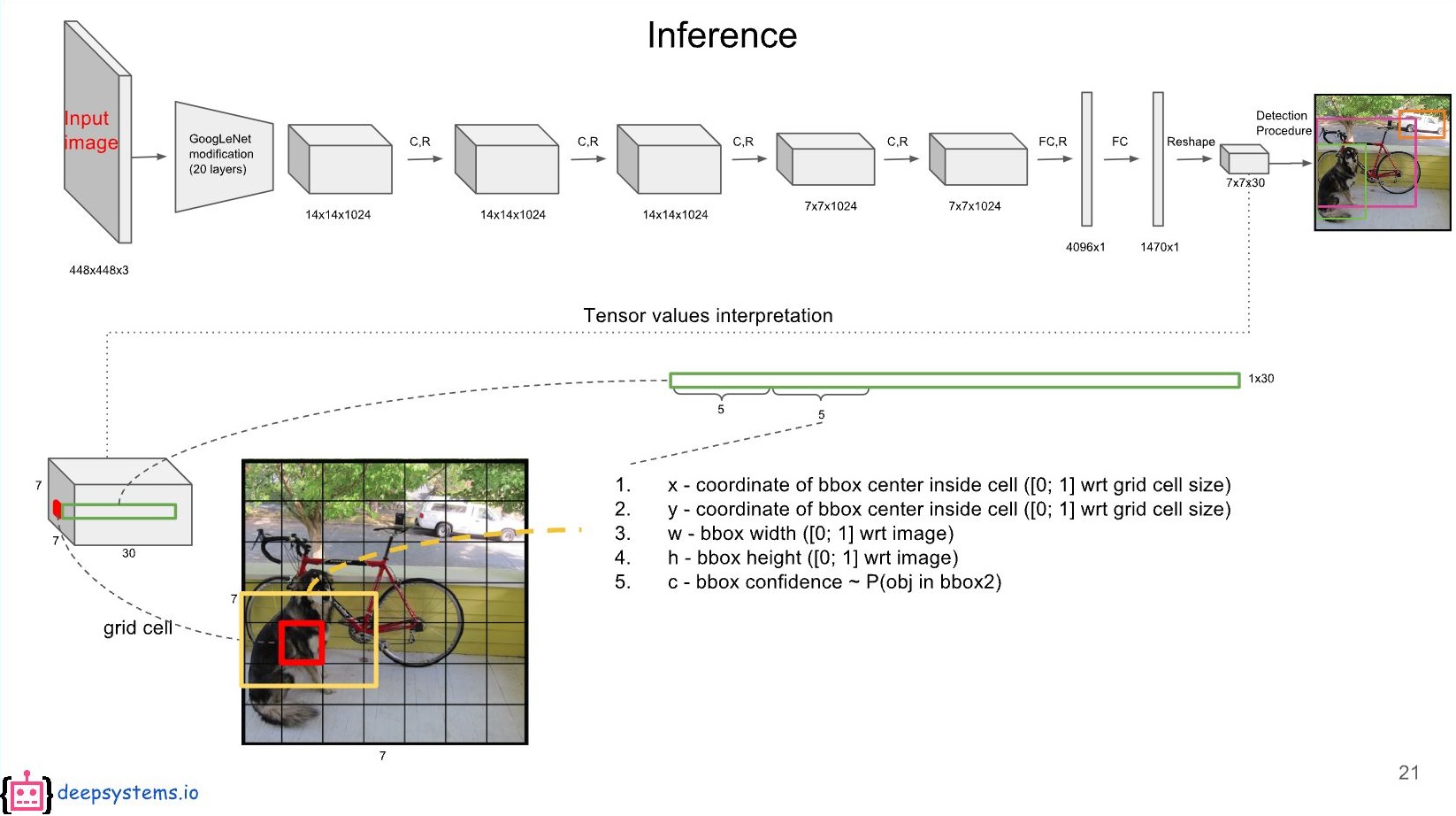
4-2-2) 두번째 Bounding Box
4-4) 각 그리드 '셀'은 클래스 개수에 대해 C를 갖는다.
- 본 글에서 C(클래스 개수)는 20으로 지정. ((예시)C1: 사람, C2: 차, C3: 자전거, 등등)
*C : conditional class probability (=probability)
*여기서 C도 개발자가 Threshold를 정합니다. 따라서 기준을 충족하지 못할시엔 박스를 그리지 않습니다.
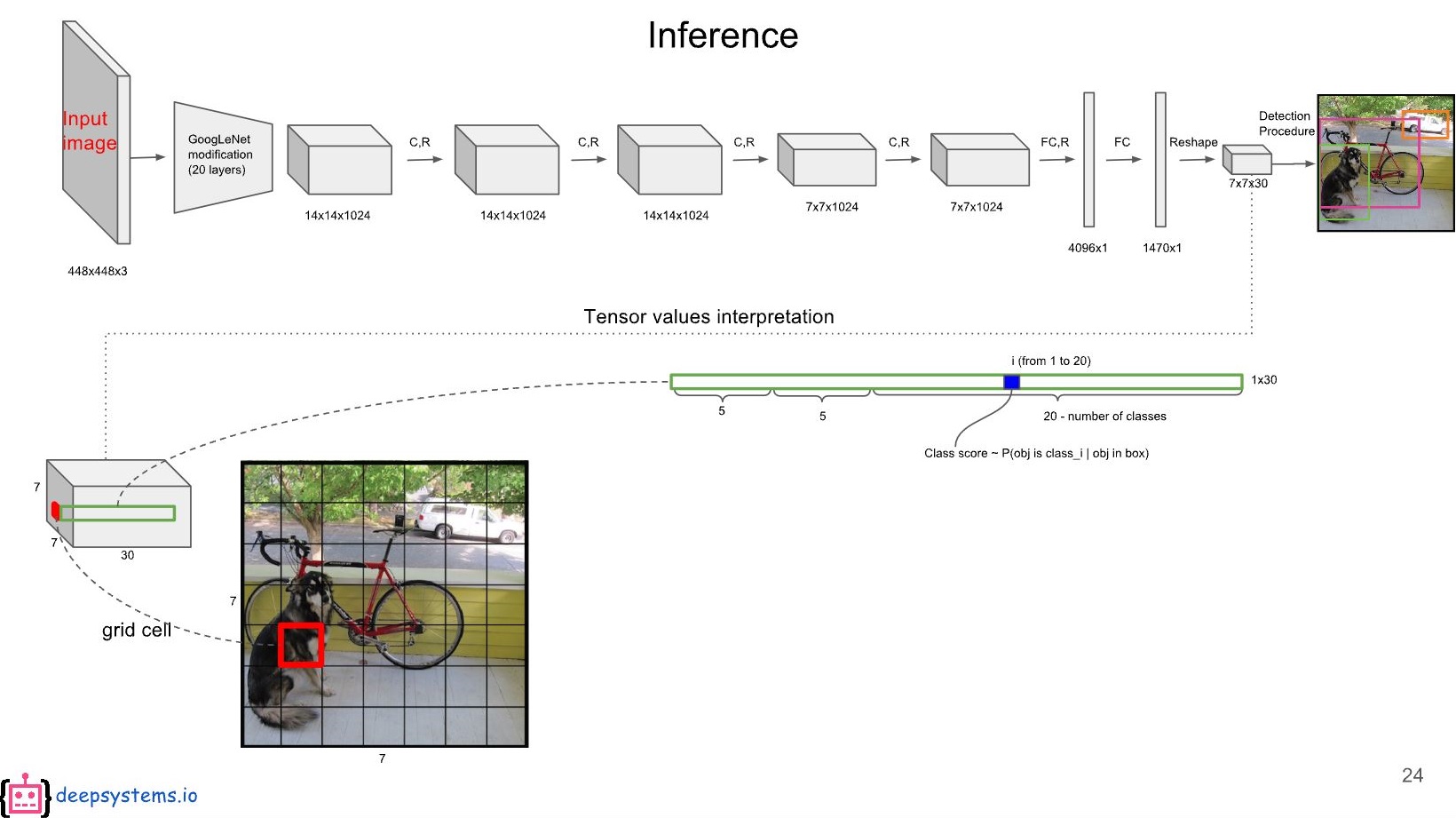
4-5) 각 셀마다 2개(Anchors)의 class-specific confidence score값을 찾습니다.
class-specific confidence score는 그 셀의 C(conditional class probability)와 각 박스의 Po(confidence score)를곱하여 한 박스에 대해 구합니다.
class-specific confidence score = C(conditional class probability) * Po(confidence score)

다른 박스에 대해서도 또 해야겠죠.

즉, 7 x 7 x 2 = 98개의 셀은 모두 class-specific confidence score를 갖게 됩니다.
5. NMS 계산
이제 98개의 Bounding Box가 나왔으므로 이걸 NMS(Non-Maximum Suppression)을 하여 중복되는 박스들을 없애줍니다.
NMS란 하나 박스를 기준을 잡고 일정 Threshold를 정한 후, 다른 박스를 비교 해 보았을때 교집합이 되는 부분이 정해진 Threshold보다 적을시 제거 하는 방법 입니다.
NMS전에 기준 BOX를 잡기 위해 Class Confidence Score를 기준으로 박스를 정렬 합니다. (Quick Sort 알고리즘 사용)
그 다음 Score가 제일 높은 박스를 기준으로 다른 박스를 순서대로 비교 하며 NMS를 진행 합니다.
YOLOv3에선 0.4 또는 0.5값으로 한다.
6. 박스 그리기
최종 박스를 그린다.
return 0;
}
'Autonomous Tech. > Machine Learning' 카테고리의 다른 글
| [Windows] 텐서플로우(Tensorflow) 사용 딥러닝 신경망 구현 - RNN 1편 [9] (0) | 2020.03.08 |
|---|---|
| [Windows] 텐서플로우(Tensorflow) 딥러닝 신경망 구현 - 네트워크 생성 [2] (0) | 2020.03.08 |
| [Windows] 텐서플로우(Tensorflow) 딥러닝 신경망 구현 - 환경 설정 [1] (0) | 2020.03.07 |
| CNN(Convolutional Neural Network) 이란? (0) | 2020.03.07 |
| [Ubuntu] PyTorch로 YOLO 돌리기 - [1] {'Installation\n';} (0) | 2020.01.28 |

