
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- tx2
- 블로그
- tensorflow
- Tistory
- 텐서플로우
- 방법
- Nvidia
- ubuntu
- Jetson
- agx
- openCV
- Darknet
- 애드센스
- 물체검출
- 파이썬
- 엔비디아
- Xavier
- 설치
- 영상처리
- cuda
- GPU
- openpose
- 딥러닝
- YOLO
- Linux
- Windows
- python
- 티스토리
- DNN
- 라즈베리파이
엔지니어스 - Engineeus
SORT(Simple Online and Realtime Tracking) 알고리즘 본문
SORT(Simple Online and Realtime Tracking) 알고리즘
Engineeus 2020. 1. 30. 00:07원리가 간단 하면서도 연산량에 큰 영향을 주지 않는 트래킹 알고리즘 이며, opensource이기 때문에 누구나 사용 가능한 코드입니다.
요즘에 영상처리에서 Yolo나 SSD 같은 Object Detection알고리즘 결과물에 붙여서 사용 하면 더 Smooth한 결과물을 보게 될겁니다.
Source Code
1. CPP 코드
https://github.com/mcximing/sort-cpp
mcximing/sort-cpp
C++ port of Simple online and realtime tracking(SORT) - mcximing/sort-cpp
github.com
2. Python 코드
https://github.com/abewley/sort
abewley/sort
Simple, online, and realtime tracking of multiple objects in a video sequence. - abewley/sort
github.com
위 파이썬 코드를 가지고 다른 블로그에서 잘 설명 해 두었습니다. 참고 하시면 좋겠습니다. 하지만 블로그에 있는 설명이 너무 직역 해 두어서 이해가 안가는 구문이 많아서, 다시 쉽게 풀어 제가 설명 하려고 글을 작성 하였습니다.
알고리즘 설명
위 C++ 코드인 이곳에 있는 코드 기준으로 설명을 해 드리겠습니다.
일단 소스파일을 보면 5개가 있습니다.
-
main.cpp
-
Hungarian.cpp
-
Hungarian.h
-
KalmanTracker.cpp
-
KalmanTracker.h
알고리즘은 C++로 구성 되어 있습니다. KalmanFilter에서 OpenCV라이브러리에 있는 함수 중 'KalmanFilter'라는 내장 함수를 끌어서 사용 하기 때문에 OpenCV 라이브브러리도 환경설정을 해 주어야 이 코드를 사용 할 수 있습니다.
main.cpp
main.cpp에서는 Tracking algorithm을 모두 담고 있습니다. 이 알고리즘의 구조는 아래와 같습니다.

main.cpp에서 SORT 알고리즘을 구동시키는 함수는 L.87(*L: Line)의 'TestSORT'에서부터 시작 합니다. 본 SORT 알고리즘을 사용 하기 위해선 이 부분을 본인의 Detector에서 나오는 Box정보들을 가지고 이 SORT에 넣어 주어야 합니다. 이 구성은 직접 하시기 바랍니다. 본 블로그 에서는 알고리즘에 대한 이해를 높이기 위해 설명만 작성 해 나가도록 하겠습니다. 사용하기 위해선 L.190 앞쪽과 L.325 뒷부분을 본인 용도에 맞도록 수정 하면 됩니다.
main loop
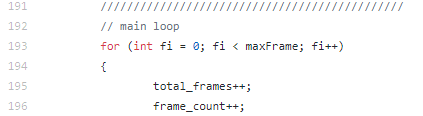
실제로 알고리즘은 L.193인 main loop에서부터 시작 됩니다.
Initialization

위 L.203은 trackers라는 container에 담긴 정보가 하나도 없을 경우 이를 L.208에서 'datFrameData.box'라는 곳의 박스 정보를 넣게 됩니다. 이렇게 하는 이유는 이후에 칼만필터를 작동 시켜야 하는데 칼만 필터는 이전 데이터를 가지고 predict(예측) 과정 연산을 하게 되는데 아무것도 없을 경우 그냥 현재 Detection된 Box의 정보로 초기화를 하겠다는 이야기 입니다. 이 과정은 컨테이너에 아무것도 없을 시 각 Class마다 딱 한번 시행 됩니다. 예를 들어 사람 얼굴을 Detection 하고 싶은데 사람 얼굴이 없다가 처음 나타날때 실행 됩니다. 그 이후 두개, 세개 나타날때는 실행 되지 않습니다. 이러다가 새로운 Class인 책이 나타나면 다시 또 실행 됩니다. 이렇게 초기화 작업을 하게 됩니다.
Prediction
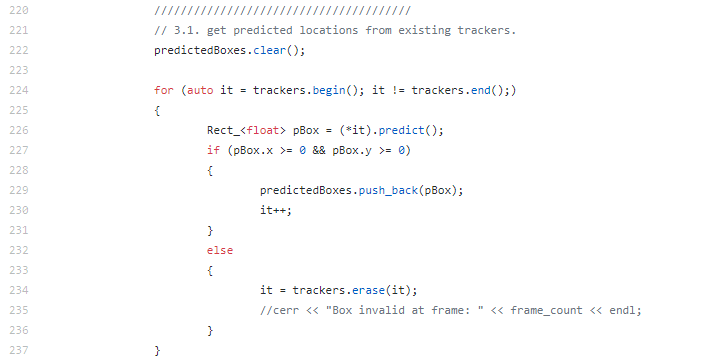
위 과정은 칼만필터에서 Predict 과정하는 겁니다. L.226에서 이 전 프레임에서 나온 최종 output인(칼만필터의 결과물)인 Box 정보를 여기서 사용 하여 L.229인 'predictedBoxes'에 넣어 줍니다. 만얀 첫 프레임 이라면 위에 Intialization에서 진행 해둔 정보가 사용 됩니다. 결과 값으로는 Xp(예측값), Pp(예측 오차공분산)이 나오게 됩니다. 이는 칼만필터를 공부 하셔야 이해가 가니 추후 따로 올리는 포스트에서 공부 하시거나 따로 검색을 통해 공부 하시기 바랍니다.
IoU

이제 어떻게 이전 Box 정보가 현 frame에서 같은 ID라고 매칭 시키는 방법을 공부 해보도록 하겠습니다.
Prediction값(이전 데이터를 통해 예측된 값)과 방금 들어온 Detection Box들이 L.253에 'GetIOU'라는 함수로 들어가서 iouMatrix에 저장이 됩니다. IoU란 Intersection over Union의 약자로 '교집합(두개의 박스가 겹치는 부분의 면적) / 합집합(두개의 박스의 모든 면적)'의 결과물이 비율로 나오게 되어 이 점수가 크면 확률상 같은 ID라고 판단 할 수 있습니다. 아래 보면 score가 클수록 더 사각형이 일치하죠.
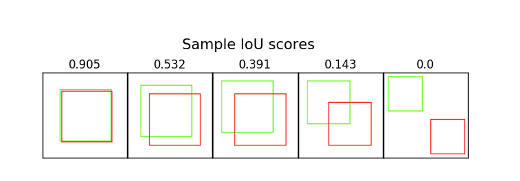
이 점수들을 iouMatrix에 모아 둡니다.
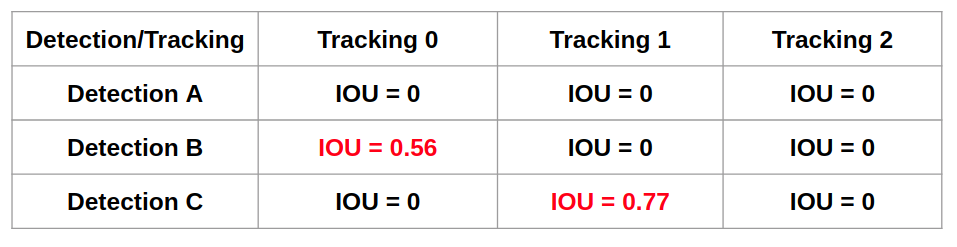
Hungarian

Hungarian 알고리즘은 최적의 matching 알고리즘 입니다. 이는 비용(연산량)을 최소화 시키는 할당 알고리즘 입니다. 매칭이 이루어 진 정보는 'assignment'에 담기게 됩니다. 이에 대한 설명은 아주 자세히 포스팅 해둔 블로그를 참조 하였습니다. 헝가리의 수학자가 만들었다고 해서 붙여진 이름 이라고 합니다.
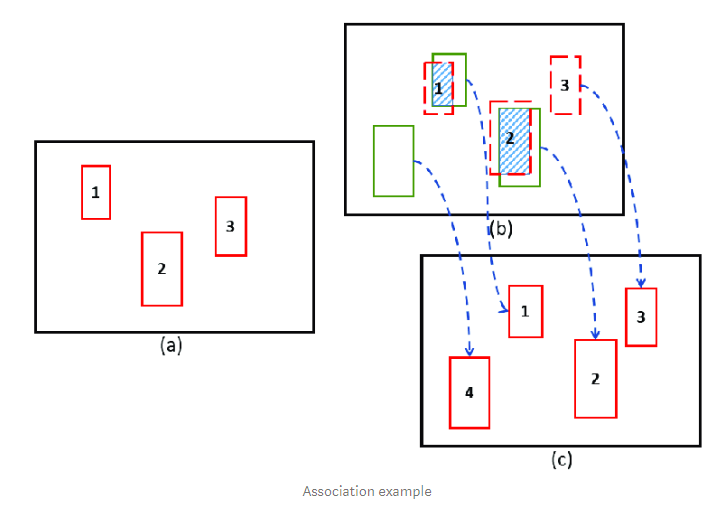
위 그림을 보면 (a)는 이전 Kalman filter에서 나온 결과이고 (b)의 초록색은 현재 Detector에서 나온 박스 입니다. 이 둘을 IoU시킨 후 Hungarian에서 짝을 찾아 주어 (c)처럼 ID가 할당이 됩니다. 새로운 박스가 있으면 4처럼생기기도 하죠.
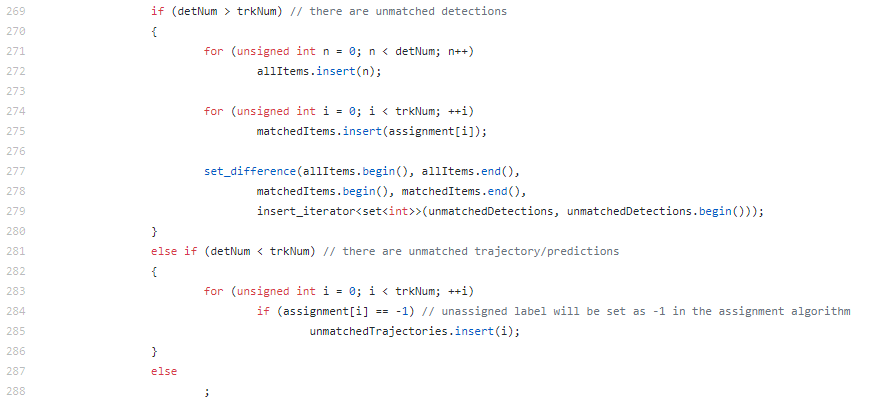
위 부분은 Detection된 allItems(모든 정보)중에 matchedItems(매칭이 이루어진 정보)와 unmatchedDetections(매칭이 이루어지지 않은 정보)들을 따로 담도록 합니다.
Filtering

위 부분은 IoU가 낮은 ID를 제거 합니다. 즉, 박스 겹친 부분이 작은 점수를 갖게 되면 이를 다시 unmatchedDetectios에 버려줍니다. 이로써 ID 매칭은 끝났습니다.
Updating
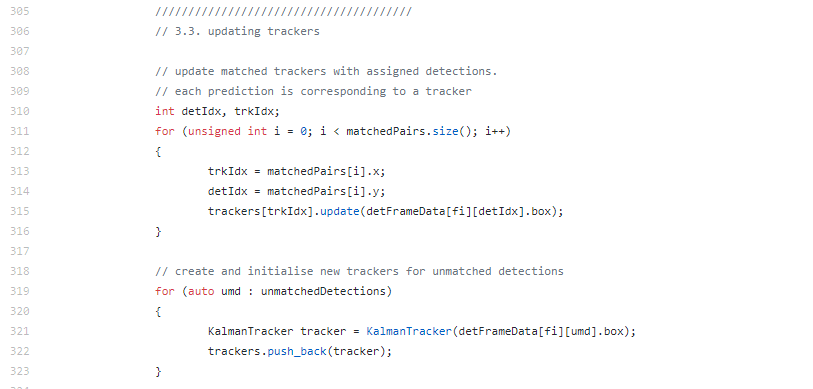
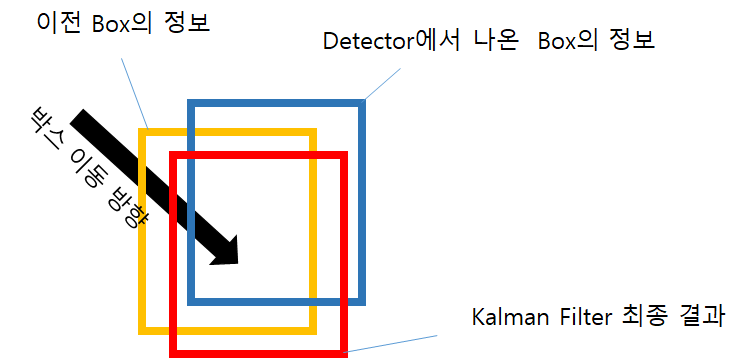
이제 ID 매칭도 끝났고 최종 정보인 Box를 그려줘야 합니다. 하지만 우리가 ID매칭을 한 이유는 ID를 알아내서 이전 Box정보로 현재 Noise가 없는 새로운 Box를 생성하도록 하기 위함 입니다. 아래 그림을 보면 이해가 됩니다. 칼만필터를 쓴 이유는 아래와 같습니다. 이동방향이 선형적으로 있는데 Detector의 결과가 위쪽으로 치우쳐지게 나오면 Box가 떨리게 됩니다. 이는 불안정해 보이게 되고 이를 해결하기 위해 이전데이터를 사용하여 새로운 위치를 예측하는 칼만필터가 적용되었으며 이로 인해 빨간색의 결과값이 나오게 됩니다.
Output
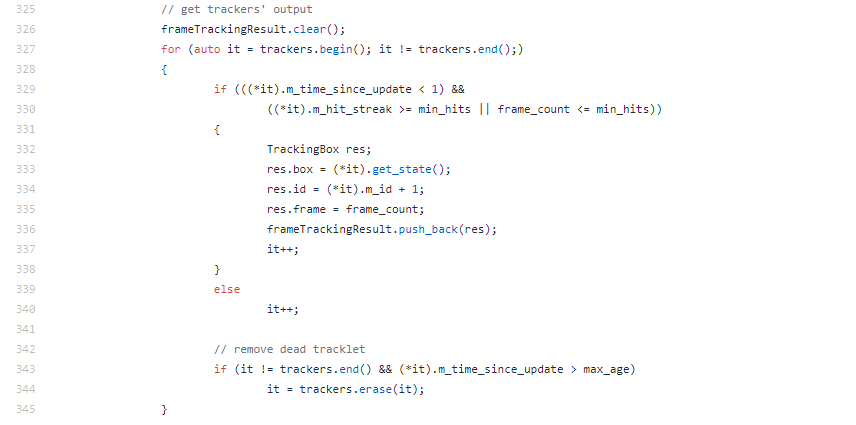
L.325에선 결과값이 res.box로 옮겨지게 됩니다. 이 결과값을 사용하여 새로 Box를 그려주면 됩니다.
이 외 Hungarian.cpp나 KalmanTracker.cpp에서는 main에서 사용하는 함수기 때문에 그다지 건드려 줄건 없습니다. 이상 SORT 알고리즘에 대한 포스팅 마치겠습니다.
'Autonomous Tech. > Image Processing' 카테고리의 다른 글
| 오픈포즈(Openpose) 공부했다. 이렇게 쉬울 줄은.. (0) | 2021.05.14 |
|---|---|
| Human Pose Estimation (휴먼 포즈 에스티메이션, 인간 자세 예측) (0) | 2021.05.14 |
| Object Tracking 이란? (1) | 2019.12.14 |
| Classification(분류) 란? (0) | 2019.12.14 |
| Object Detection이란? (0) | 2019.12.14 |



